Note: This notebook was originally developed as part of the ICESat-2 2020 Hackweek Machine Learning tutorial (Instructors: Yara Mohajerani and Shane Grigsby). A recording of the tutorial is available here. The original source repository is at ICESAT
-2HackWeek /Machine -Learning.
Inference using Bayesian Networks¶
Inference is a powerful technique that combines empirical evidence and prior statistical beliefs to determine likelihood from causal connections. A classic example is presented below in graphical form (taken from this blog; please excuse the convention of substituting commas for decimal places):
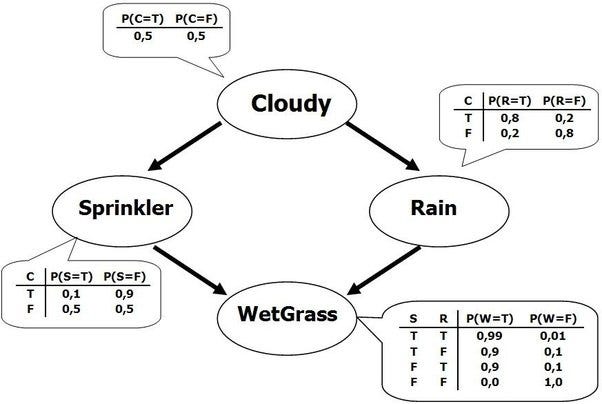
Source: miro.medium.com (via Towards Data Science)
As shown above, there are two causal explanations for why the grass is wet-- the sprinkler could be on, or it could have rained. We can enter the graph at any point to infer the conditional likelihood of each variable; for example, if we know the state of cloudy, we can replace the 50/50 prior probability, and propagate that through the graph. We can also reverse the direction; if we know that the grass is wet, we can infer the empirical likelihood of cloudy being true such that it is weighted by this evidence, instead of just the prior belief. Note that this means that it is possible to determine prior beliefs from data, by choosing an naive prior and replacing after acquiring empirical data.
The classical example above maps to ICESat-2 data with some simple modifications. Let’s sat that you observe an ICESat-2 QAQC flag that the data is “not useful”, caused by the ATL06 algorithm failing to find the ground. There are several possible causal reasons for this: the surface could be obscured by optically thick clouds; the surface could be complex because of crevassing; there could blowing snow on the surface; there could be an instrument issue. If we discount the last option of instrumentation error, we can pull out useful information from the QAQC flag about the physical process that is causing the flag. If we have cloud data (i.e., from another data source like VIIRS), or wind data, we can start to build a statistical inference pipeline that will infer the likelihood of blowing snow or crevasses.
Numeric Considerations¶
Bayesian nets can be used as simple feed forward networks (if we are confident in our priors), or trained to determine the conditional probabilities that the network itself uses. We’ll use pymc3 in this notebook to examine how to formulate and build Bayesian networks-- first using discrete variables, then expanding to incorporate continuous variables. All of this falls under probabilistic programming; there a wide variety of tasks that the framework can be used for. The pymc3 library uses Monte Carlo simulations for inference, which can sped up substantially by GPUs-- although they run just fine on CPUs as well.
Defining a Probabilistic Model¶
We’ll use a worked epidemiology example to show how to set both static parameters, and distributions over parameters, and then explore adding in empirical observations to the model.
%pylab inlinefrom IPython.display import Image
from IPython.display import Markdown as mdimport pymc as pm
from pymc import Normal, Model
from pymc.math import switch
import arviz as az
Image('./_BayesianBeliefNets/a4Murphy1.jpg')# General model
Image('./_BayesianBeliefNets/a4Murphy2.jpg')with Model() as bayesnet:
# Parent
g1_healthy = pm.distributions.discrete.Bernoulli('g1',0.5)
# Latent variable that conditions the children
g1_L = switch(g1_healthy > 0.5, 0.9, 0.1)
# Left Child
g2_healthy = pm.distributions.discrete.Bernoulli('g2', g1_L)
# Right Child
g3_healthy = pm.distributions.discrete.Bernoulli('g3', g1_L)
# Conditional switches for blood pressure mean
rate1 = switch(g1_healthy > .5, 50, 60)
rate2 = switch(g2_healthy > .5, 50, 60)
rate3 = switch(g3_healthy > .5, 50, 60)
# Parent and children
x1 = Normal('x1', mu=rate1, sigma=10**.5)
x2 = Normal('x2', mu=rate2, sigma=10**.5)
x3 = Normal('x3', mu=rate3, sigma=10**.5)pm.model_to_graphviz(model=bayesnet)We see that the defined model is identical to the reference figure, just with being placed in below rather than above. The ‘G’ parameters are all Bernoulli distributions that specify a binary outcome. The ‘’ variables are continuous distributions of blood pressure.
Exercise 1¶
Compute P(G1 = 2 | X2 = 50). This is the probability that the parent () has the heredity disease given that the child () has blood pressure of 50.
# Compute P(G1 = 2 | X2 = 50)
with Model() as bayesnet:
# Parent
g1_healthy = pm.distributions.discrete.Bernoulli('g1',0.5)
# Latent variable that conditions the children
g1_L = switch(g1_healthy > 0.5, 0.9, 0.1)
# Left Child
g2_healthy = pm.distributions.discrete.Bernoulli('g2', g1_L)
# Right Child
g3_healthy = pm.distributions.discrete.Bernoulli('g3', g1_L)
# Conditional switches for blood pressure mean
rate1 = switch(g1_healthy > .5, 50, 60)
rate2 = switch(g2_healthy > .5, 50, 60)
rate3 = switch(g3_healthy > .5, 50, 60)
# Grandkids and child
x1 = Normal('x1', mu=rate1, sigma=10**.5)
# Setting x2 as an observed variable
x2 = Normal('x2', mu=rate2, sigma=10**.5, observed=50)
x3 = Normal('x3', mu=rate3, sigma=10**.5)Note that the above is identical to our original model definition-- the only thing that has changed, is that we have set as an observed variable. There is an analytic solution to this type of inference, but we’ll use sampling to estimate an empirical solution:
with bayesnet:
mytrace = pm.sample(10000, tune=2000)We see that PyMC3 does the hard work of choosing the appropriate samplers for us :-) The binary variables use Gibbs Metropolis-Hastings, and the continuous use the No-U-Turn-Sampler. The variable is not sampled, since we set it as observed. The result of the sampling is a trace; we can view the trace to get our answer to the original question (although it will take a second to plot given the sample size):
az.plot_trace(mytrace);The original question was “what’s the probability that the parent has the disease”, so we can take the number of samples where (is healthy), and divide by the total number of samples to get the percentage of the population in the simulation that was healthy:
p_g1_healthy = mytrace.posterior['g1'].values.flatten().sum()/len(mytrace.posterior['g1'].values.flatten())
p_g1_not_healthy = 1 - p_g1_healthy
p_g1_healthy, p_g1_not_healthymd("""We find {}% of the G1 samples are healthy (G1 = 1); so {}% are unhealthy (G1 = 2).
We can actually access the same information using the `summary()` function, which will also
provide an error estimate:""".format(p_g1_healthy.round(4)*100,p_g1_not_healthy.round(4)*100))az.summary(mytrace)stats = az.summary(mytrace, var_names=['g1'])
err = round(float(stats['mcse_mean'].iloc[0]),5)
plus = round(float(1-stats['mean'].iloc[0] + stats['mcse_mean'].iloc[0]),5)
minus = round(float(1-stats['mean'].iloc[0] - stats['mcse_mean'].iloc[0]),5)
ans = round(float(1-stats['mean']),5)
md("""As mentioned, we could analytically compute the answer:
- The analytic answer is 0.10535
- The MCMC estimate is {} +/- {}
Since 0.10535 is between {} and {}, seems that we did well.""".format(ans,err,plus,minus))Brief digression on MCMC error¶
I was curious about the MCMC error... does the sampler actually know how good a job it’s doing? Running the sampler again with a factor less samples certainly gives a worse estimate:
with bayesnet:
mytrace = pm.sample(2000);p_g1_healthy = mytrace.posterior['g1'].values.flatten().sum()/len(mytrace.posterior['g1'].values.flatten())
p_g1_not_healthy = 1 - p_g1_healthy
p_g1_healthy, p_g1_not_healthyaz.summary(mytrace)stats = az.summary(mytrace, var_names=['g1'])
err = round(float(stats['mcse_mean'].iloc[0]),5)
plus = round(float(1-stats['mean'].iloc[0] + stats['mcse_mean'].iloc[0]),5)
minus = round(float(1-stats['mean'].iloc[0] - stats['mcse_mean'].iloc[0]),5)
ans = round(float(1-stats['mean']),5)
md("""The new answer is {} +/- {}. Given that the analytic answer is 0.10535, this
is clearly a worse estimate... but 0.10535 still falls within the {} to {} bounded
error envelope, so we know the answer is less precise. If we need more precision, we can
simply run more samples till the MC error is acceptably low.""".format(ans,err,minus,plus))Exercise 2¶
Compute P(X3 = 50 | X2 = 50). That is, what is the conditional probability that child 2 () has blood pressure equal to 50 given that their sibling (child 1, ) has normal blood pressure (50). As before, we simply fix the variable of interest using the observed flag:
with Model() as bayesnet:
# Parent
g1_healthy = pm.distributions.discrete.Bernoulli('g1',0.5)
# Latent variable that conditions the children
g1_L = switch(g1_healthy > 0.5, 0.9, 0.1)
# Left Child
g2_healthy = pm.distributions.discrete.Bernoulli('g2', g1_L)
# Right Child
g3_healthy = pm.distributions.discrete.Bernoulli('g3', g1_L)
# Conditional switches for blood pressure mean
rate1 = switch(g1_healthy > .5, 50, 60)
rate2 = switch(g2_healthy > .5, 50, 60)
rate3 = switch(g3_healthy > .5, 50, 60)
# Grandkids and child
x1 = Normal('x1', mu=rate1, sigma=10**.5)
x2 = Normal('x2', mu=rate2, sigma=10**.5)
# Setting x3 as an observed variable
x3 = Normal('x3', mu=rate3, sigma=10**.5, observed=50)with bayesnet:
mytrace = pm.sample(25000)Because the variable that we’re interested in is continuous, it isn’t as obvious how to answer our question... we could of course cheat, and cast as discrete value:
n1 = mytrace.posterior['x2'].values.flatten()>51
n2 = mytrace.posterior['x2'].values.flatten()<50
(len(mytrace.posterior['x2'].values.flatten()) - sum(n1) - sum(n2))/len(mytrace.posterior['x2'].values.flatten())The analytic solution is 0.10306, so casting as a discrete variable gives a close approximation, but is also kinda unsatisfying because:
The width for the approximation isn’t always obvious. Here, for blood pressure, using a natural number is a pretty clear fit-- but this isn’t as obvious for other cases.
We don’t have an error estimation on the approximation. This seems not very Bayesian.
We could also try to cheat an answer by reading directly off of the trace plots:
az.plot_trace(mytrace);df = mytrace.posterior.to_dataframe().reset_index(drop=True)df.x2.hist(bins=200,density=True)df.x2.plot.kde()Since we’ve fixed , we don’t see it in the plots, but we do get the variable that was previously omitted when it was fixed. We can see that the probability for = 50 is close to our analytic solution, and we don’t have to decide a width, but:
We still don’t have an error estimate on the parameter
We’re just eyeballing a value off of a graph. There’s surely a more numerically precise way to do this...
Estimating a numerically robust solution¶
My preferred solution is to estimate an empirical PDF (Probability Density Function) via KDE (Kernel Density Estimation) using the trace of as the input. This allows probability estimation of any value, including decimal values:
from scipy.stats.kde import gaussian_kdemy_pdf = gaussian_kde(mytrace.posterior['x2'].values.flatten())my_pdf(50)This treats the continuous variable as continuous, so there is no need to decide an integration width. It is also numerically precise. For error bounds, we can still get them from the trace summary (using the mc_error):
az.summary(mytrace)This works because we have a numerically precise value of the probability, so we can port the error estimates over. We couldn’t do this using the first window method because we were looking over a range interval, and didn’t have a precise estimate when looking at just the trace graphs.
Another thing to note-- because statistics are built of an empirically sampled distribution that is rendered via simulation, we are able to retrieve answers from distributions that are not classic well behaved Gaussian’s. The distributions and are not well behaved; they cannot be approximated by a Gaussian, and it’s unclear if they could be even be modeled by a combination of classical statical functions. But, using MCMC estimation, we fundamentally don’t care what the output distribution looks like; we can query the trace for probability information regardless of it’s form. As more explicit example:
# We'll complicate our sampling by adding in more data
# pymc3 allows observed variables to be numpy arrays, pandas
# dataframes, or theano data structures; so you can add
# quite a bit of empirical datadata_1 = [38,58,62,55,80,40,51,52]
data_2 = [32,110,72,43,66,55,59,52]with Model() as bayesnet:
# Parent
g1_healthy = pm.distributions.discrete.Bernoulli('g1',0.5)
# Latent variable that conditions the children
g1_L = switch(g1_healthy > 0.5, 0.9, 0.1)
# Left Child
g2_healthy = pm.distributions.discrete.Bernoulli('g2', g1_L)
# Right Child
g3_healthy = pm.distributions.discrete.Bernoulli('g3', g1_L)
# Conditional switches for blood pressure mean
rate1 = switch(g1_healthy > .5, 50, 60)
rate2 = switch(g2_healthy > .5, 50, 60)
rate3 = switch(g3_healthy > .5, 50, 60)
# Grandkids and child
x1 = Normal('x1', mu=rate1, sigma=10**.5)
x2 = Normal('x2', mu=rate2, sigma=10**.5, observed=data_2)
# Setting x3 as an observed variable
x3 = Normal('x3', mu=rate3, sigma=10**.5, observed=data_1)with bayesnet:
mytrace = pm.sample(5000)az.plot_trace(mytrace);Above tells us that the Bayesian estimate is certain that one child has the condition, and is fairly certain that the other doesn’t. This means that the parent is more likely to have the condition than not; also note that the blood pressure likelihoods are highest for each case associated with the condition (compared to a mean).